BaikalTeam
We make internet projects accessible round the clock.
Servers and network infrastructures are our area of expertise.
With our help they become stable and efficient.
We are a team of professionals who love cutting-edge technology. Startup and well-established companies seek our help in creating and maintaining stable and scalable infrastructures for their business needs. In return we develop server and network infrastructures for their projects according to their demands.
-
 Commitment is everything
Commitment is everything Controlled perfectionism
Controlled perfectionism Passion for the profession
Passion for the profession Aimed at strategic partnerships
Aimed at strategic partnerships
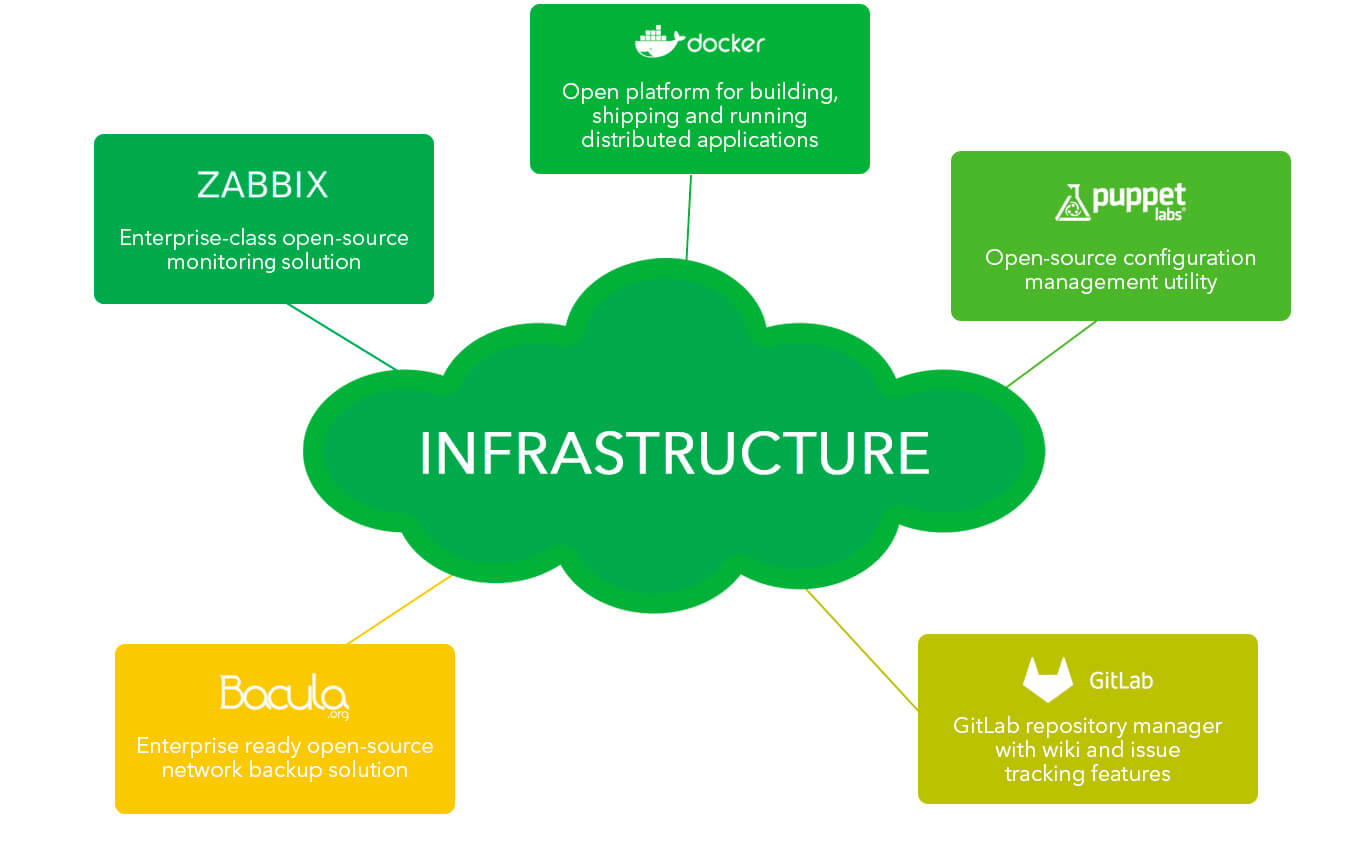
The growing internet company began having difficulties with its infrastructure. It was possible to set up its servers manually because there weren't many. But when the number of servers grew, so did the problems with cross-platform compatibility. BASH scripts were then used to create a backup, but its quality couldn't be controlled. The company faced other issues: no centralized monitoring, problems with code deployment, etc.
The first thing to do was to update software on all of the company's servers. Then the configuration files had to be made uniform. The configuration files management system Puppet maintained control over the accuracy of the configuration files and versions of the installed software.
We applied a solution called Bacula to manage backup files, which made the process more stable. Also we saved time during each backup because we copied only files that had differed from the last backup run.
We used Zabbix to monitor the infrastructure's real-time condition. If any anomalies arose in the infrastructure, our team and our clients were immediately notified by e-mail and SMS. Thanks to this feature we could resolve problems before users of web services could notice.
We installed GitLab, a local repository, and used Docker to organize the process of code deployment on production servers. Docker helped us to cut code deployment time to under 1 minute.
We installed up-to-date services to better manage infrastructures. We saved time on the following scalable infrastructure and avoided service failures thanks to a properly selected architecture of infrastructure and the way we monitored infrastructure condition and managed configuration files.
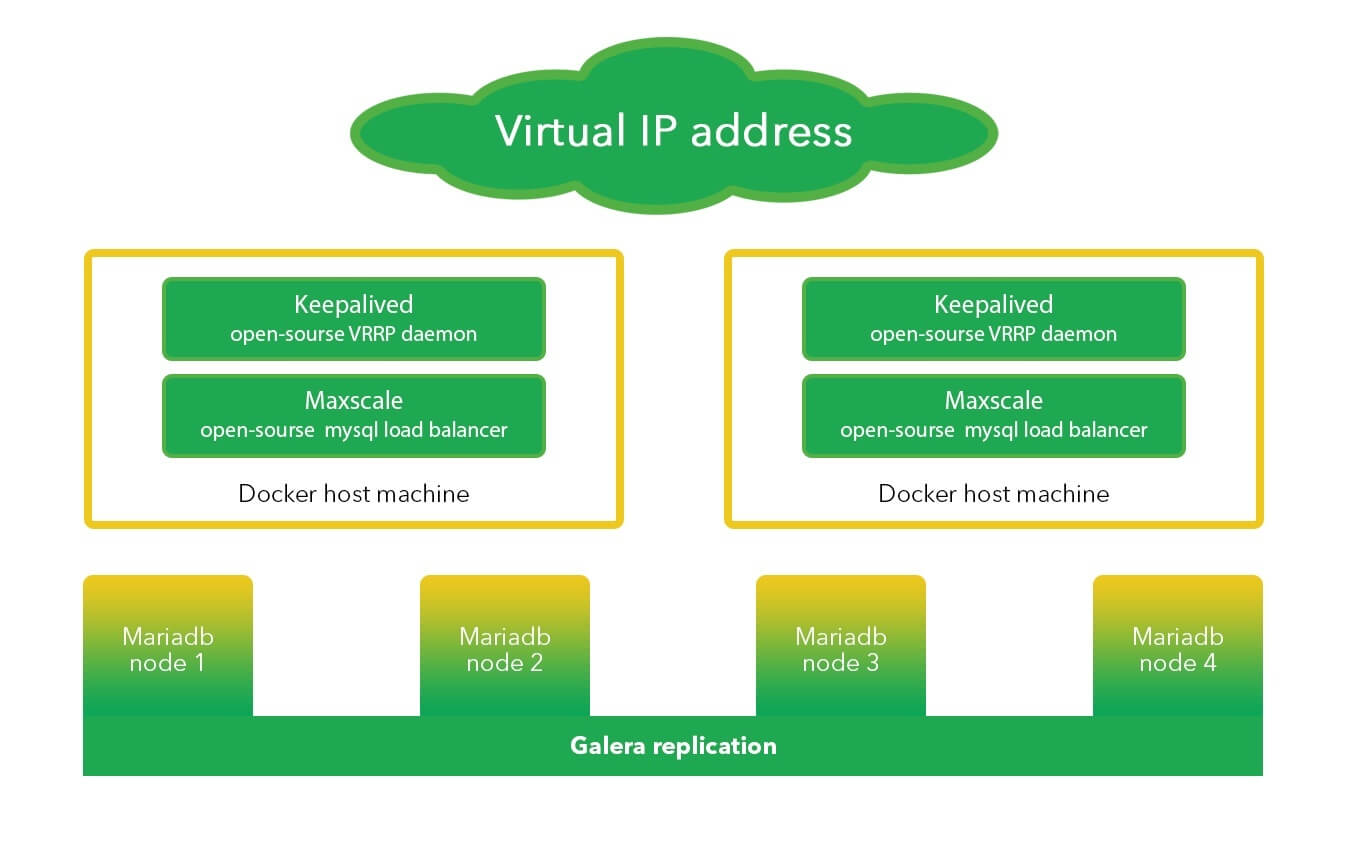
After a massive crash happened during work on the databases, the internet service had to find a solution to organizing a high availability and high load database service which could allow work to be saved even in cases of hardware malfunctions.
So, we developed a cluster with three logical levels: It was MySQL nodes, the replication between which was done with the help of Mariadb Galera Cluster. Galera guarantees complete synchronicity among all nodes and enables them to join up during load increments.
Mariadb Maxscale controls load balancing between nodes. We split up read and write queries across different servers and created a filter for write queries to guard data from being damaged (for example, DELETE without WHERE). We also made it possible to set any node to maintenance mode, the operation of which did not hinder the cluster’s availability.
With VRRP we created high availability servers that come equipped with load balancing capabilities. In case of a hardware malfunction, Keepalived automatically switches the virtual IP address over to a backup load balancer.
We increased the level of availability and efficiency of MySQL databases and eliminated downtime that occurs whenever a service component breaks down. Also we used a MySQL database cluster and applied a Mariadb Galera cluster for synchronization, Maxscale for load balancing across database servers and Keepalived for maintaining high availability on the VRRP base.
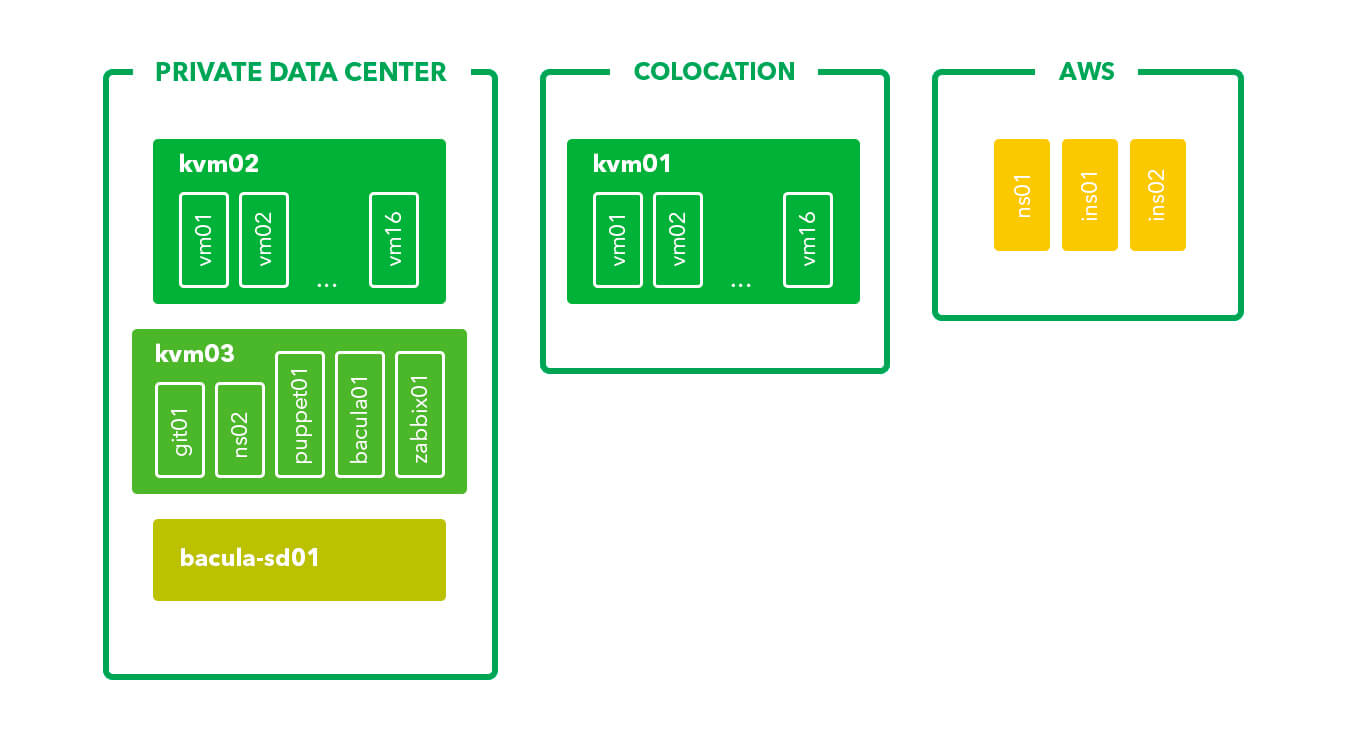
Web Studio debuted internationally and set off with helping clients complete their projects around the world. Web resources were then placed on platforms located near clients in order to speed up page loading times. As their client base expanded, extra measures were taken to improve methods of data storage to decrease the risk of data loss.
To do this three web project platforms were strategically placed: one in the private data center of the client for customers in and around Russia, the second at the AWS base for clients headquartered in North America, and the third at a colocation base in Amsterdam for European clients.
The client's platform is equipped with two servers for KVM virtual machines. It has a RAID 10 logical drive with the capacity to decrease risk of data loss. These servers contain virtuals machines with web projects and virtual machines for internal systems (git repository for developers, a monitoring system, configuration files management tool, and one of the DNS servers for DNS zone customers). We launched Bacula storage daemon as a data storage server for backup files. It was stored separately to improve data security.
Several instance for web projects and the second DNS server were launched on Amazon EC2. By using Amazon RDS, we were able to provide database storage.
To set up a platform in Europe, we placed a server at colocation in Amsterdam. There a large AMS-IX internet exchange point is located, which reflects positively on response times
We put out three platforms for hosting at different geographical locations and developed ways for managing infrastructures.
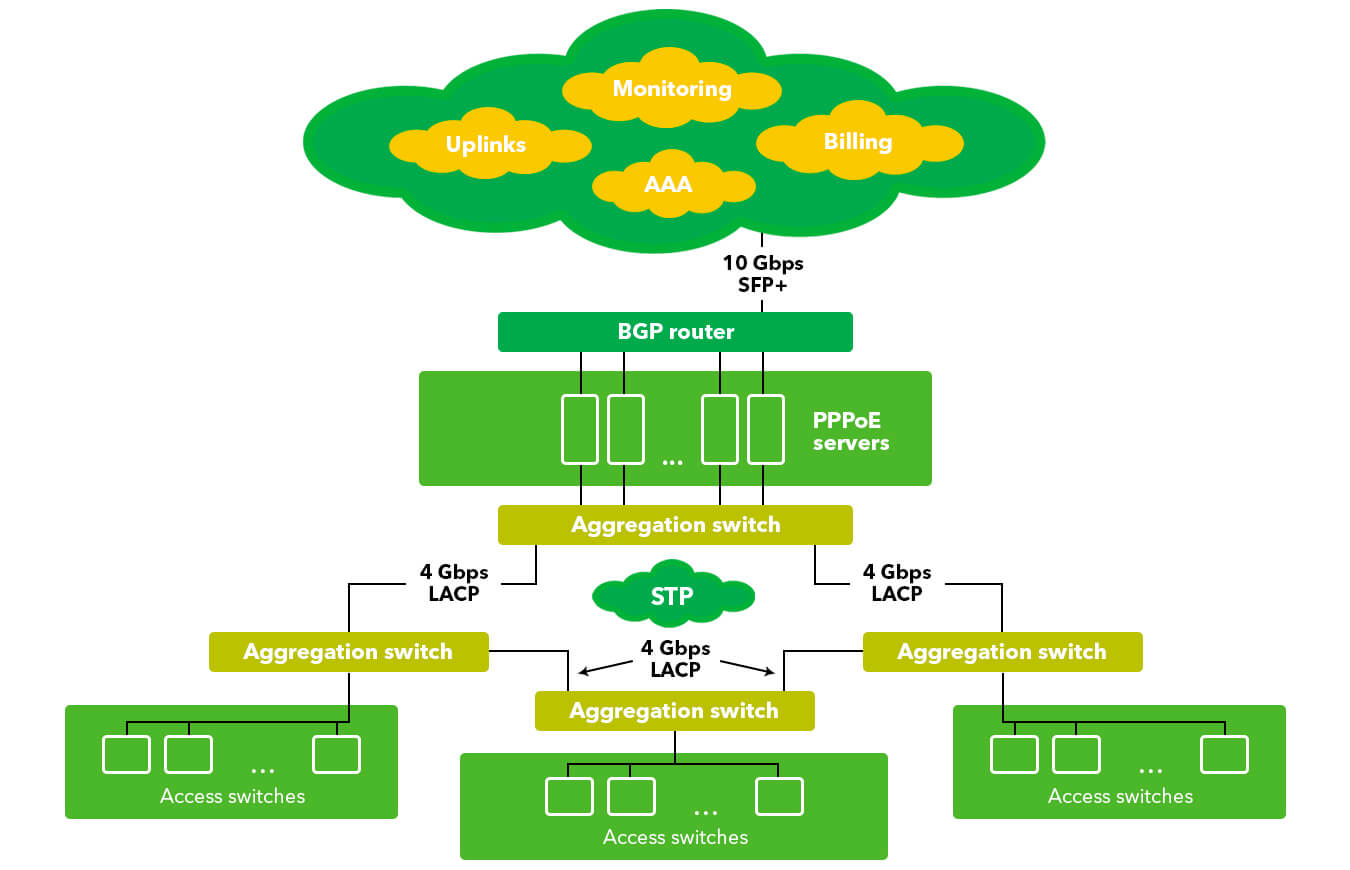
The ISP decided to build networks in a new microregion which needs to be designed accordingly in order to minimize loss of service to subscribers in case of a malfunction.
As a solution the network was divided into several logical elements: termination level, aggregation level and access level.
On the level of termination we placed a group of PPPoE servers. This group was reserved according to the N+2 scheme in cases of malfunction or upsurge in load (for example, on New Year's holidays). We balanced the servers by adjusting the speed of response to connection queries.
Aggregation nodes were connected from termination points along a ring network. Spanning Tree carried out the task of backing up connective channels.
Access nodes were connected from aggregation nodes along a star network (the topology was selected based on the budget for installation costs).
Each node was equipped with an uninterrupted power supply capable of lasting between 1 to 16 hours, depending on the node’s activity levels.
We expanded the network of ISP through a project of designing and optimizing the high availability segment of aggregation and termination level of subscribers.